
文字列を比較する仕組み、比較する方法(完全一致、大小比較 等)を説明します。
文字列を比較する仕組み
文字列の比較はUnicodeのコードポイントを用いた辞書式順序
文字列 (
https://docs.python.org/ja/3/reference/expressions.html#id12strのインスタンス) の比較は、文字の Unicode のコードポイントの数としての値 (組み込み関数ord()の返り値) を使った辞書式順序で行われます。
便宜上、下記のグループを定義する。同一グループの文字のみで構成された文字列の比較は正しく辞書順で比較されます。
- アルファベット小文字
- アルファベット大文字
- 数字
- カタカナ
- ひらがな
上記となる理由は、同一グループの文字はUnicode上に、辞書順で連続的に配置されているためです。例えば、数字であれば、0から9の順に0x0031から0x0039に配置されています。下記はUnicode一覧(数字、アルファベット、カタカナ、ひらがな)です。

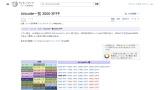
順序の決定
【ルール1】
最初の二つの要素を比較し、その値が等しくなければその時点で比較結果が決まります。等しければ次の二つの要素を比較し、以降シーケンスの要素が尽きるまで続けます。比較しようとする二つの要素がいずれも同じシーケンス型であれば、そのシーケンス間での辞書比較を再帰的に行います。二つのシーケンスの全ての要素の比較結果が等しくなれば、シーケンスは等しいとみなされます。
https://docs.python.org/ja/3/tutorial/datastructures.html#comparing-sequences-and-other-types
#①
print("a" < "b")
"""出力
True
"""
#②
print("abc" < "abd")
"""出力
True
"""
- ①
- 最初の2つの要素を比較した結果、値が等しくないので比較結果が決定しています(“a”が”b”より小さい)。
- ②
- “ab”までは値が等しいので、”c”と”d”の比較により、比較結果が決まっています。”c” < “d”なので、文字列としても”abc” < “abd”となります。
【ルール2】
片方のシーケンスがもう一方の先頭部分にあたる部分シーケンスならば、短い方のシーケンスが小さいシーケンスとみなされます。
https://docs.python.org/ja/3/tutorial/datastructures.html#comparing-sequences-and-other-types
print("ab" < "abd")
"""出力
True
"""
注意点(正確な辞書順で比較されない場合があります)
ひらがなはカタカナよりコードポイントが小さいため、下記の様に、正確な辞書順で比較されません。
print("あ" < "ア")
print("あめ" < "アメ")
print("やかん" < "アメ")
"""出力
True
True
True
"""
比較する方法
大小比較
<, >を用いて比較することができます。
print("1" < "2")
print("11" < "12")
print("1" < "12")
"""出力
True
True
True
"""
print("1" > "2")
print("11" > "12")
print("1" > "12")
"""出力
False
False
False
"""
完全一致
==を用いて比較することができます。
print("1" == "1")
print("あ" == "あ")
print("あ" == "ア")
print("雨" == "雨")
"""出力
True
True
False
True
"""
参考
String comparison technique used by Python – Stack Overflow
sorting – How do I sort unicode strings alphabetically in Python? – Stack Overflow

コメント